Facebook Paper and Copyright screens
by Wojciech Adam Koszek ⋅ Sep 8, 2015 ⋅ Menlo Park, CAMy amazement with number of modules modern mobile app can consists of.
In the process of working on Sensorama I wanted to get inspired by a well designed modern mobile app. Figuring out the libraries and technologies people use in well designed products is often a good way to go. Even Apple uses existing products as a base for their next products. But how to find out more about software internals?
Legal pages are those boring documents that none of us ever usually reads. But they are also a great source of engineering information. As makers of software, due to legal and copyright issues, we need to give credits to authors of the libraries we use, as well as inform users about potential risks. And no - you can’t just use the copy & paste function, obfuscate it with your own variable names, reformat tabs to spaces and shift a few lines here and there. Technically you’re supposed to credit people for their work. Basically: help people who have written free code to put their names out there in the wild so that now and then they might land some consulting gigs in exchange for free (as in “free beer”) tools.
Getting back to boring screens: of course software copyright information holds nothing of value for a normal person. However, I believe that every software person sooner or later will end up on the copyright and help screens of applications which they like, as they search for the ultimate truth. The Facebook Paper copyright screen, for example, surprised me:
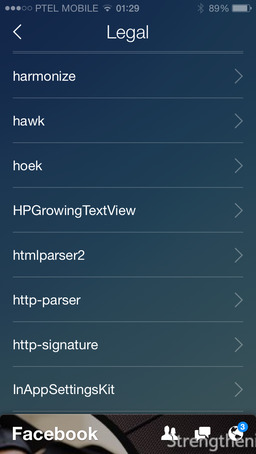
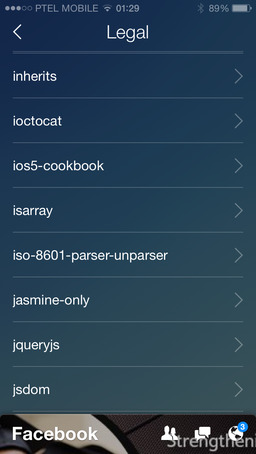
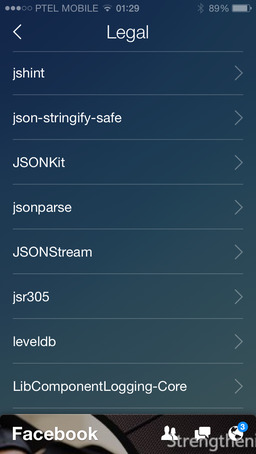
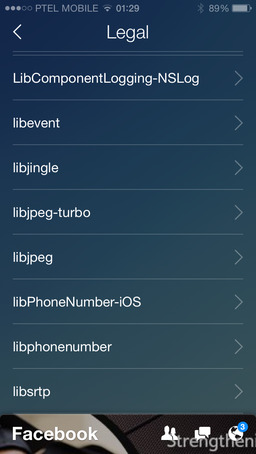
It’s actually 31 screens, listing ~240 items, both libraries and plugins. Even though it looks interesting, it may mean two things: Facebook Legal makes sure that the engineers behind the Paper app paste the notification every time they borrow the code, regardless of how small and common it is, and/or this number of libraries is actually being used inside Paper. The former is quite likely, since at Xilinx we used to do this too (why pay $10M for litigations, lawyers and patent attorneys, if you can fix it with a paranoid license screen?). Regardless of either possibility, big kudos to Facebook for recognizing Open Source.
At Xilinx there was a license scrubbing script, which made sure that all licenses from all pieces of contributed software were collected in one place. After spotting some files without copyright information and seeing that they could accidentally be tagged as proprietary, we got little paranoid. In a big corporation once you make such a mistake, further analysis is very difficult. Basically: who knows what your next intern will copy & paste to the software product when you are not looking?! [1] FreeBSD does the same, so I guess it’s a common industry practice.
If somebody from the Paper team is reading this, maybe we’ll get to know some more on how Facebook is tackling the problem of contributed code and what does it really take in order for the library to be mentioned.
Contributed code has always posed a challenge to me. A pattern I’ve observed: you start engineering your project from a nicely written build infrastructure such as Makefiles which builds very quickly. The moment you have to reach out and get some additional library to help you out with things it all starts to look so-so: autoconf, automake, autoreconf, left-overs from post-configure stages, Makefiles referring to other Makefiles etc.. Once you have it all built and working fine, you realize it’s only the beginning of the journey. On your to-do list is now frequently checking whether any security advisories for the contributed code have been published, and figuring out why your build doesn’t work on a Mac or over NFS…
This all makes me wonder: how do you attack the problem of contributed code and copyrights of libraries that you have taken advantage of? How big would your copyright screen be if you did it properly?
[1] Just joking. The review process in my group was very strict. It is unlikely that people could just add weird-looking code without others noticing.